
 首 頁
首 頁阮彤:ChatGPT等大語言模型對醫(yī)療信息系統(tǒng)的影響與提升——大語言模型在醫(yī)療行業(yè)應(yīng)用系列(一)
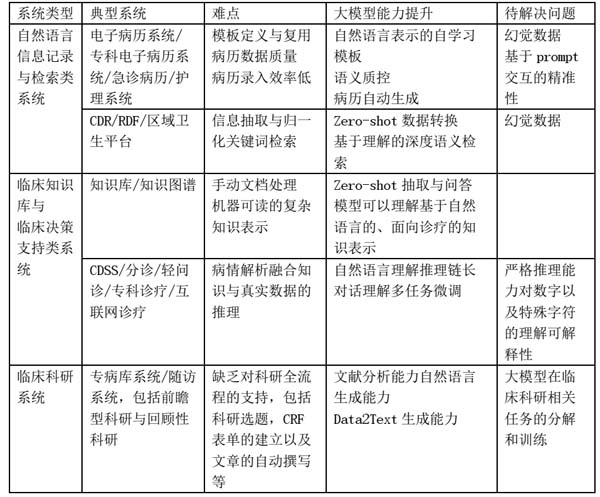
類ChatGPT的語言模型對于包括醫(yī)療在內(nèi)的各行各業(yè)系統(tǒng)的沖擊是本質(zhì)性的,由于語言模型會推動人機交互方式的變化、代碼與文檔的自動生成、數(shù)據(jù)的自動分析處理,因此,本質(zhì)上,會影響所有信息系統(tǒng)。但是,比較重要的變遷可能在三大類系統(tǒng)上,自然語言信息記錄與檢索類系統(tǒng)、臨床知識庫與臨床科研系統(tǒng)三大類知識/數(shù)據(jù)密集型系統(tǒng)上。下表列出了這些系統(tǒng)類型對應(yīng)的典型系統(tǒng),原有系統(tǒng)的難點,以及大模型的能力帶來的可能的提升,以及應(yīng)用大模型同時可能出現(xiàn)的待解決的技術(shù)問題。
表1 大語言模型會改變的系統(tǒng)

1自然語言信息記錄與檢索類系統(tǒng)
原本就與自然語言有關(guān)的,帶有模糊性和個性化的系統(tǒng),會有更大的變化與受益。比如說,電子病歷系統(tǒng)、區(qū)域衛(wèi)生共享平臺、專病庫系統(tǒng)等,由于數(shù)據(jù)格式很難達到共識,給系統(tǒng)的構(gòu)建與變遷帶來困難。很長時間以來,業(yè)界希望通過信息化標(biāo)準(zhǔn)、互聯(lián)互通協(xié)議、專病數(shù)據(jù)模型等來規(guī)范系統(tǒng)的數(shù)據(jù)格式,但因為數(shù)據(jù)格式問題非常瑣碎,因此,推廣過程困難重重。這個問題的本質(zhì)在于,凡是用自然語言描述的東西,都有豐富的語義,而任何一種規(guī)范,都會損失語義,從而限制未來各種可能的表達。
大語言模型的特點在于強大的自然語言理解與生成能力。該能力衍生出了不同格式文檔的理解與生成,數(shù)據(jù)格式的語義轉(zhuǎn)換,數(shù)據(jù)的自動化的清洗等等。更重要的是,這些能力的激發(fā),并不需要標(biāo)注大量語料,Zero-Shot、Few-Shot InContext learning以及一些簡單的自然語言提示(prompt),就可以達到比較好的效果。微軟的office將可以通過簡要描述,生成用戶需要的文檔,而文本抽取任務(wù)、文獻檢索在Zero-Shot以及簡單的示例情況下就可以有比較好的效果。下表顯示了面向中文文本的醫(yī)療的CBLUE評測在chatGPT上的基本效果。
表2 CBLUE在chatGPT上的測試效果

上述的文本生成功能,將對電子病歷系統(tǒng)/專科電子病歷系統(tǒng)/急診病歷/護理系統(tǒng)等系統(tǒng),產(chǎn)生較大的影響。電子病歷系統(tǒng)的核心功能是可定制的EMR模板,以及基于模板的引導(dǎo)式數(shù)據(jù)錄入。難點并不在于定制模板,而是模板定義規(guī)范很難確立,對模板的擴充限制,會影響模板的靈活性,但如果不限制,又會影響模板的利用。而有了大模型,可以放入大量的經(jīng)典例子進行指令微調(diào),然后通過使用簡單的提示(prompt),表達模板的含義,生成相應(yīng)的病歷數(shù)據(jù)。而電子病歷的質(zhì)控,也完全可以通過prompt定義質(zhì)量要求,再自動生成,或是修改過程,或是輸入完成后,進行質(zhì)量控制。其他功能,如導(dǎo)入檢驗檢查數(shù)據(jù),或是文檔的修改,都可以通過自然語言交互接口完成。
大模型對于文檔的轉(zhuǎn)化、清洗以及檢索和分析功能,將對醫(yī)院的CDR/RDR/專病庫系統(tǒng)產(chǎn)生影響。智能檢索與數(shù)據(jù)轉(zhuǎn)換是傳統(tǒng)的CDR/RDR系統(tǒng)的兩大難點。基于關(guān)鍵詞的檢索,由于同義詞、上下位詞、否定、遠程依賴等醫(yī)療詞匯、語法以及語義層面的特點的存在,遠遠不能達到CDR系統(tǒng)電子病歷篩選數(shù)據(jù)的要求。由于檢索和利用的困難,萌生了大量的數(shù)據(jù)轉(zhuǎn)換需求,RDR和專病庫系統(tǒng),所謂的文本結(jié)構(gòu)化,數(shù)據(jù)歸一化,本質(zhì)上就是利用數(shù)據(jù)格式統(tǒng)一,簡化分析利用的困難。而大模型的Zero-Shot的數(shù)據(jù)轉(zhuǎn)換能力,不僅會給各種快速的數(shù)據(jù)轉(zhuǎn)換帶來方便,也會讓業(yè)界不再執(zhí)迷于數(shù)據(jù)格式,而是側(cè)重于確認(rèn)數(shù)據(jù)包含的語義。
大模型對于區(qū)域衛(wèi)生平臺的好處更為顯見。長期以來,區(qū)域衛(wèi)生平臺通常會有統(tǒng)一的數(shù)據(jù)采集規(guī)范,對醫(yī)院上傳的數(shù)據(jù)字段具有復(fù)雜而又詳盡的格式要求。為了制定這個規(guī)范,通常需要多家醫(yī)院協(xié)商,在不同信息能力的醫(yī)院之間平衡。而為了執(zhí)行這個規(guī)范,又在采集過程增加了很多質(zhì)量檢測。即使如此,由于電子病歷包含的數(shù)據(jù)字段豐富,數(shù)據(jù)冗余且值域難以規(guī)范化,文案之間的語義關(guān)系含混,并有大量的自然語言和影像文件,因此,區(qū)域平臺的數(shù)據(jù)利用一直是很大的難點。而和CDR以及RDR平臺類似,有了大語言模型,對于數(shù)據(jù)規(guī)范變得不那么嚴(yán)格,醫(yī)院端數(shù)據(jù)的格式轉(zhuǎn)化,數(shù)據(jù)的質(zhì)控,會更為語義化,數(shù)據(jù)的檢索和利用,特別是多模態(tài)數(shù)據(jù)檢索和利用,會更有想象空間。
2知識庫與臨床決策支持類系統(tǒng)
傳統(tǒng)的知識庫構(gòu)建通常采用人工手段,從醫(yī)書、臨床指南,醫(yī)學(xué)文獻中抽取知識。這種抽取過程不但費時費力,而且更新困難。更糟糕的是,知識圖譜等結(jié)構(gòu)化的方式雖然精確,但語義表達能力遠遠弱于自然語言,包括多元關(guān)系、條件關(guān)系,因果關(guān)聯(lián)等等各種知識模式的定義,需要很高的專業(yè)認(rèn)知能力和業(yè)務(wù)建模能力,而模式的理解和正確性驗證也同樣有雙重門檻。另外,加工后的知識庫,由于應(yīng)用場景不一,和場景結(jié)合時,又需要二次加工,也讓知識庫成為某種“雞肋”型應(yīng)用。
臨床決策支持系統(tǒng),就是知識庫系統(tǒng)的這樣一個“雞肋”應(yīng)用。從理論上說,我們以診斷和治療兩個關(guān)鍵決策為例,說明其中的難點。
診斷難點在于對疾病進行猜測,以及基于猜測的進一步的檢驗檢查,評估診斷的好壞,不僅在于猜測的精準(zhǔn)度,檢驗檢查的合理性,也在于迭代交互式的過程方便性。而達到上面的目標(biāo),除了需要對病人病情數(shù)據(jù)的更為完整的觀測和了解,對各種疾病出現(xiàn)可能性的概率判斷,也需要比傳統(tǒng)知識庫查詢更好的交互手段,需要更為場景化的決策支持系統(tǒng)的設(shè)計與評估方式。因此,基于傳統(tǒng)知識庫的臨床診斷,基本上只能作為文獻查詢輔助用途。
而治療的問題,在于個人病因,病情發(fā)展以及個體各種個性化特征,包括多疾病共存與并發(fā)疾病等等,知識庫系統(tǒng)很難將共性和個性治療方法的描述,以及各種異常情況的判斷,用結(jié)構(gòu)化方法描述。而在臨床決策系統(tǒng)中,也很難將特定病情和知識庫的條目簡單關(guān)系起來。
大語言模型對文本數(shù)據(jù)的解析能力,極大方便了知識庫系統(tǒng)的構(gòu)建。而自然語言檢索和問答,提升了知識庫的應(yīng)用的便利性。大語言模型體現(xiàn)的推理能力,提供了智能醫(yī)學(xué)診斷和治療方案推薦的可能性。具體而言,可以通過chatGPT的開源框架langchain的一系列工具,以及chatGPT的各種Zero-Shot抽取能力,將原始書本數(shù)據(jù)抽取成更為合適的形式。而對于臨床決策類的知識庫應(yīng)用,在提升知識庫對嵌套、條件、分支和異常、概率等各種表達能力基礎(chǔ)上,綜合更多的真實世界數(shù)據(jù)。可以將病人病情通過大模型進行解析,在知識庫上進行推理。也可以將知識自動生成數(shù)據(jù),與真實數(shù)據(jù)一起,放入大模型進行訓(xùn)練。當(dāng)然,大模型的可解釋性、不穩(wěn)定性以及缺乏嚴(yán)密的邏輯推理等問題,也會給臨床決策支持帶來障礙,可以通過分解決策的步驟,通過外接知識庫,對推理的每一步進行嚴(yán)格溯源與控制得到緩解。
3臨床科研系統(tǒng)
從大類來說,臨床科研和AI for Science話題有關(guān)。其中,生物信息的基因、蛋白、突變、病毒等數(shù)據(jù),可以看作是一大類模態(tài),訓(xùn)練的大模型可能帶來的生信領(lǐng)域的重大變革。本文討論的是臨床醫(yī)生日常的科研:包括選擇題目、構(gòu)造CRF表單、病人招募、臨床數(shù)據(jù)采集、科研數(shù)據(jù)分析以及科研論文撰寫等為流程的科研過程,一般分為前瞻性研究和回顧性研究。
對于回顧性研究,由于整個過程由于完全是基于數(shù)據(jù),LLM將從選題到撰寫論文,帶來流程性的時效性的重大變革。首先,原來的選題和構(gòu)造CRF表單的過程,需要調(diào)研文獻、或是在RDR上分析臨床數(shù)據(jù),找到可能的方向,這個過程可能在早期需要人類的思考和假設(shè),但一旦思考過程可以記錄在案,形成類模板的思考鏈,就可以通過對于文獻的自動分析和數(shù)據(jù)分析,獲得可能的研究方向與字段。對于臨床數(shù)據(jù)采集,如前文所說,利用大模型的數(shù)據(jù)轉(zhuǎn)換能力,可以快速把數(shù)據(jù)轉(zhuǎn)換成CRF表單需要的格式。對于論文撰寫,由于此類論文本身在模式上有大量的雷同,而差別主要是病種不同,數(shù)據(jù)不同以及數(shù)據(jù)結(jié)果分析不同。目前的基于數(shù)據(jù)到文本生成技術(shù),再綜合一些常見的模板,文章初稿生成,可以達到一定的效果。理論上,回顧性研究,通過面向特定訓(xùn)練目前的LLM模型,可能可以達到端到端的效果。如果是前瞻性研究,有動態(tài)收集數(shù)據(jù)的過程,可以看作是在特殊訓(xùn)練的LLM模型上增加了一個外在的插件。
除了前面所說的系統(tǒng)外,影像和病理檢查系統(tǒng),本身就在被人工智能提升,多模態(tài)模型的出現(xiàn),為直接寫出影像檢查文本,提供了可能性。 也有些系統(tǒng)影響比較小,如HIS、LIS、HRP等涉及財務(wù)、藥品、檢驗等交易與結(jié)算類醫(yī)療業(yè)務(wù)系統(tǒng)。但如我們所說,由于大模型本身在交互方式、數(shù)據(jù)統(tǒng)計以及文檔與代碼生成的能力,這些系統(tǒng)未來也一定會發(fā)生變革。
當(dāng)然,目前大模型還存在很多問題,包括穩(wěn)定性、可解性等等。對于醫(yī)療行業(yè)來說,最直接的是技術(shù)的可獲得性問題,因為醫(yī)療數(shù)據(jù)不可能外接到ChatGPT或其他外部運營的大模型上,這就意味著必須要有自己可控的、較為廉價的類似模型。因此,在后面的幾次文章中,我將詳細闡述如何獲得這些能力,以及每個不同系統(tǒng)使用大模型的不同的方法。
作者簡介
阮彤,CHIMA委員,華東理工大學(xué)信息科學(xué)與工程學(xué)院計算機系,博導(dǎo),教授。現(xiàn)任華東理工大學(xué)計算機技術(shù)研究所所長,自然語言處理與大數(shù)據(jù)挖掘?qū)嶒炇抑魅巍iL期從事自然語言處理、知識圖譜、醫(yī)學(xué)人工智能等方面的研究。
