
 首 頁
首 頁阮彤:醫療系統獲得大語言模型能力的途徑——大語言模型在醫療行業應用系列(二)
大模型生態以令人恐懼的速度發展,每天都會有新的開源模型,新的訓練軟件包,訓練數據,以及形形色色的基于大模型的應用。從大模型開源社區Hugging face,到開源框架LangChain,到Meta的開源模型LLAMA,到可以廉價訓練的LORA預訓練的方式,以及具有規劃和整合能力的AutoGPT,大模型對于普通用戶的可獲得性越來越強。大模型應用形式越來越豐富,而代價越來越低。
本文將探討醫療行業如何快速使用大模型的各種能力,體驗新技術帶來的好處。因為新系統的探索和應用需要時間和各種資源的投入,因此,本文從淺入深,給出了應用落地的順序,使得最終用戶可以以較小的代價受益于技術。
另外,本文僅探討技術能力,醫學以及醫療行業可能涉及到的倫理、安全與政府監管等,包括開源軟件商用合法性等,都是重要話題,但此處不進行詳細探討。
一可選技術方案
目前可用的技術方案可以分為三大類:
1.使用現有ChatGPT/GPT4模型,采用插件或其他方式接入大模型,過程中利用大模型的自然語言理解或是自然語言生成能力。
OpenAI提供了官方的插件API,可以用于定制客戶化的應用,如檢索網絡與內部知識庫信息,執行科學計算,調用外部工具等。OpenAI目前的插件包含了各種應用,如查詢詞匯含義,餐廳預定,查詢航班、酒店信息,差旅規劃,訪問電商數據,比價甚至直接下單等。官方演示中包含了ChatGPT接入數學知識引擎Wolfram Alpha,實現精準的數學計算。
最早是使用OpenAI的接口,寫一個簡單的Prompt完成需要的功能。但這種方法工作量比較大。因此,在插件推出之前,比較流行的是用LangChain框架。該框架面向ChatGPT等大語言模型設計一系列便于集成到實際應用中的接口,降低了在實際場景中部署大語言模型的難度。LangChain框架基于不同的場景,提供了不同的接口。最簡單的是通過Prompt Template訪問,復雜的如QA Chain、SelfASK Chain等,可以基于外部文檔生成問答,或是將大模型的思維鏈和外部數據源關聯起來。另一種方法是使用Agent接口,系統將調用大模型接口,將自然語言指令轉化為面向特定應用的調用。此外,LangChain集成了Anthropic、Palm等多種大模型接口,可以在不同的模型之間切換。更加值得注意的是,LangChain和多個向量庫、外部知識庫集成,為訪問外部數據提供了良好的支撐。
2.使用開放模型,在模型上進行持續預訓練和指令微調。
很多情況下,由于數據的安全性,技術上的穩定性以及特殊任務要求,領域用戶需要將模型部署在自己域內,因此,擁有一個屬于自己的大模型成為基本需要。這時候,領域用戶可以部署開放模型,或是在開放模型上,基于自己領域任務特殊要求,構造訓練數據,再次進行訓練。
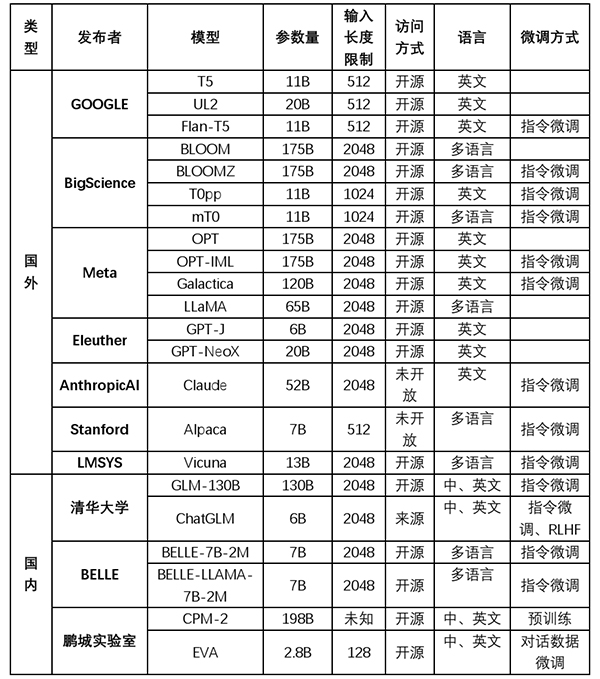
大模型的訓練分為三個步驟:首先是預訓練,基于目前比較流行的是Decoder或是Encoder-Decoder結構,相比而言,Decoder由于模型簡單且速度快,GPT等模型均采用的該架構。這個步驟使得模型能記錄海量的知識;其次是有監督微調,即利用用戶的監督數據,對模型參數進行調整。這個步驟使得指令可以誘導和激活相應的知識;最后是人類反饋的強化學習,即通過人類的反饋,進行調整模型的結果。這個步驟使得模型的答案與人類的判斷更為吻合,但并不增加模型的能力。目前可用的開放模型如下表所示:
表1 目前可用的部分開源模型

其中,BloomZ是在Bloom上微調獲得,而ChatGLM是在GLM基礎上,以監督微調與人類反饋強化學習等技術經過中英雙語訓練得到,Alpaca、Belle和Vicuna是在LLAMA微調,分別對應的是英文指令、中文指令以及對話數據。另外,由于LLAMA只用于科研目的,受限比較多,最近Databricks發布了Dolly 2.0,基于ELeutherAI Pythia模型系列,允許各種商用目的。
對于醫療領域,由于數據和應用有自己的特點,可以構造自己的指令數據集合,然后在開源模型進行訓練,具體采用的模型可以根據資源以及任務的難易進行選擇。數據構造一般有兩種方式,一種是通過self-instruct方式,利用ChatGPT的能力獲得,一種是利用任務中已有的數據,通過清洗后,自行設計提示模板并將其轉換成相應的監督數據。另外,如果領域數據有自己的特性,在微調之前持續預訓練可能是需要的,這時候可能需要比較多的計算資源。
3.從頭訓練一個大模型。對于大型客戶,可以自己采集互聯網語料,疊加電子病歷數據、醫術與文獻數據,構造純領域模型。
雖然ChatGPT線路一直將大數據量、大參數量合并算力,作為技術的準入門檻。但是,為什么模型需要那么多語料以及參數,目前還沒有公開的解釋。同時,正是因為ChatGPT大模型展現的令人震驚的能力與價值,大量科研人員通過數據采樣或是蒸餾等策略,減少語言模型所需要的資源。因此,行業頂級用戶,從頭訓練自己的大模型,是可以預期的將來。
二醫療機構嘗試前需要考慮的問題
前文說到,電子病歷系統、CDR/RDR系統、區域衛生平臺、知識庫、診療、臨床科研等系統,利用大模型都可以有比較好的提升。但是從落地角度,到底先嘗試哪些呢?本文從代價角度,基于技術和業務門檻,由簡單到復雜進行排序。一般來說,采用哪一種解決方案,需要思考下列幾個問題:
1.是否需要非開放的專有數據?
如果有專有數據,如電子病歷數據,則可能需要放在內部,不能提交給ChatGPT。雖然ChatGPT相關的檢索解決方案,可以從技術上比較好的解決檢索問題,但電子病歷,即使是向量化的電子病歷,是否可以提交給ChatGPT,目前也沒有共識。
2.是否現有的ChatGPT能力能滿足這個應用?
這個問題需要做比較多的測試,因為有時候可能是prompt或是例子寫得不合適,導致ChatGPT效果不好,這時候,做合適的Prompt Engineering就可以了。如果不行,就可能需要做指令微調。比如說實體抽取和關系抽取,表面上是ChatGPT能直接滿足的,但對于帶有數字標號的一些特殊實體,常常會有幻覺出現。
3.如果不能滿足,有沒有比較大的業務、數據或技術門檻?
技術門檻很難確定,可以看看常見的指令微調數據集合有沒有類似的任務,如果有,則可能門檻會比較低一點。比如說電子病歷生成,由于基于Prompt的生成任務是大語言模型的一個常見任務,所以雖然可能需要對電子病歷文本進行預訓練,同時在生成的效果,交互的方式,以及質量的控制等方面都有待探索,但比起互聯網問診還是要方便很多。因為問診不僅需要有復雜的追問和判斷邏輯,需要豐富的知識,而且經常會融合多模態數據,結果又需要高度的精準。因此,相對而言就比較復雜。
4.有幾張GPU卡?是A100以上的,還是其他?
如果沒有,那就只能使用現有運營的模型,如果有多張4090 GPU卡,根據存儲大小,考慮部署開源模型,或是做一些基于LORA模式的指令微調。如果有多張A100,可以考慮較大范圍的指令微調以及基于LORA模式的持續訓練。
三應用嘗試順序與方案
基于這四個問題的答案,建議應用機構可以按照下列順序嘗試大模型技術。
1.知識庫與文獻檢索系統 使用ChatGPT+LangChain等。由于不涉及內部數據,可以基于現有ChatGPT的LangChain框架以及相關應用直接完成。首先匯集自己常用的醫學書籍和文獻。其次抽取或解析這些文件,并使用向量庫方式,對文檔進行語義檢索。進一步的,可以根據知識庫目標,構造問題與多個問題之間的關聯,抽取相關書籍和文獻,然后組織成較為結構化的形式,供相關用戶瀏覽。
2.電子病歷檢索系統 使用開源模型+微調。根據前期作者在部分電子病歷上的測試結果,ChatGPT語言模型對電子病歷的敏感度是相當高的,只是數據可能不能放到外網。預計基于開源語言模型的搜索,也會比現有的關鍵詞搜索效果要好。如果不能獲得很好的效果,進行一些持續訓練或者預訓練,應該能取得比較好的效果。
3.RDR/區域衛生平臺/專病庫 采用開源模型+微調/復雜Prompt。這些系統的核心除了檢索之外,會有較多的數據清洗與不同類型的數據轉換。這個過程一步完成效果可能不會太好。預計需要多個步驟完成,而步驟的分解,以及每個Prompt怎么寫,需要進一步實驗。
4.電子病歷錄入 采用開源模型+微調/復雜Prompt。有了很好的語義檢索和數據轉換功能,電子病歷錄入就可以集中在內容的撰寫,而不是格式的要求上。基于Prompt生成會有幻覺現象,另外,電子病歷語言有自己的風格,不同專科電子病歷也有特定的要求,如何將這種要求同時讓醫生和機器了解,需要挑選更為經典的用例,更多的微調以及比較好的Prompt設計。
5.臨床科研 采用ChatGPT/開源模型+類AutoGPT框架。這個方向前期在于問題解析和調研,中期在于獲取數據以及數據分析,后期在于基于數據的論文撰寫。任務有較大的復雜度和各種整合要求,但由于本身對精準度要求并不高,同時也可以有用戶的交互,因此準入門檻并不高。這個工作早期可以也通過ChatGPT的各種軟件拼接完成。
6.決策支持系統 采用開源模型+微調+外接知識庫+推理+圖像OCR解析+長上下文。如前文所說,決策系統類型豐富,涉及到的技術點較多,可能還會補充各種檢查報告結果,對于普通機構來說,可以在特定決策應用上,比如,預問診、體檢報告閱讀,或是特定專科上進行嘗試。
與上述任務相關的,是上述任務效果的評估。目前電子病歷檢索、數據清洗與轉換、電子病歷錄入、決策支持等,都缺乏合適的判斷標準,以及相應的標準數據集合進行測試。特別的,對于電子病歷錄入,還需要通過大規模的RLHF進行提升。而對于決策支持,需要提高決策過程的可解釋性,才能真正的讓醫生和病人信服。
四總結
前文給出了由易到難的嘗試次序,對于醫療機構來說,可以按照這個次序進行技術實驗。對于企業,需要結合自己的優勢業務進行實驗。對于研發機構,在日新月異的技術前面,盡量選擇門檻較深的方向進行研究。我們將在后續的文章中,逐步給出每類系統的方案或是核心功能演示。
作者簡介
阮彤,CHIMA委員,華東理工大學信息科學與工程學院計算機系,博導,教授。現任華東理工大學計算機技術研究所所長,自然語言處理與大數據挖掘實驗室主任。長期從事自然語言處理、知識圖譜、醫學人工智能等方面的研究。
